
Large Language Models (LLMs) are moving fast, however integrating them to real-world applications, data, and tools remains challenging. This limitation poses difficulties when developing practical applications, as LLMs cannot remember long conversations, don’t know about recent events or trends, and cannot directly access files or tools. This is where the Model Context Protocol (MCP) comes in.
During this blog we’ll explore why MCP is needed, break down its core architecture, highlight its key benefits like standardization and simpler development, and clarify how it relates to existing techniques like RAG. Whether you are building AI applications or are simply curious about the future of this technology, you will understand why MCP could be a crucial element in the AI era.
Introduction to Model Context Protocol (MCP)
Why do we need MCP?
Large Language Models (LLMs) like GPT, Claude, or DeepSeek are incredible and powerful, but when you start building real apps with them, you hit some walls pretty quickly. Here’s the deal:
- Context Window Limits: LLMs can only process a finite amount of text (tokens) at once. This limit makes it hard or impossible to give the LLM all the full history it might need.
- Cost & Efficiency: Sending large histories or documents repeatedly to fit within that context window increases API costs and can slow down responses.
- They’re stuck in time: An LLM only knows information up to its training cutoff. It cannot answer questions about recent news or updates -> LLMs are disconnected from real-time information happening now.
- Can’t touch your computer: An LLM running on a server somewhere can’t access files or run commands on your local machine. It’s isolated.
Okay, so how does MCP help?
Model Context Protocol (MCP) standardizes communication to improve interactions between LLMs and external data sources. Instead of relying only on the LLM’s built-in limitations, MCP enables more powerful AI applications by allowing:
- ✅ Long, context-aware conversations that don’t get lost.
- ✅ Seamless integration of external tools and APIs into the chat flow.
- ✅ Access to relevant, up-to-date, and private information when needed.
💡 The Big Win: Standardization = Interoperability
Because MCP focuses on standardization (like how USB provides a standard way to connect devices), it aims for interoperability.
Below is a simple analogy to help you understand the concept of MCP, illustrated like a smart USB hub for AI.
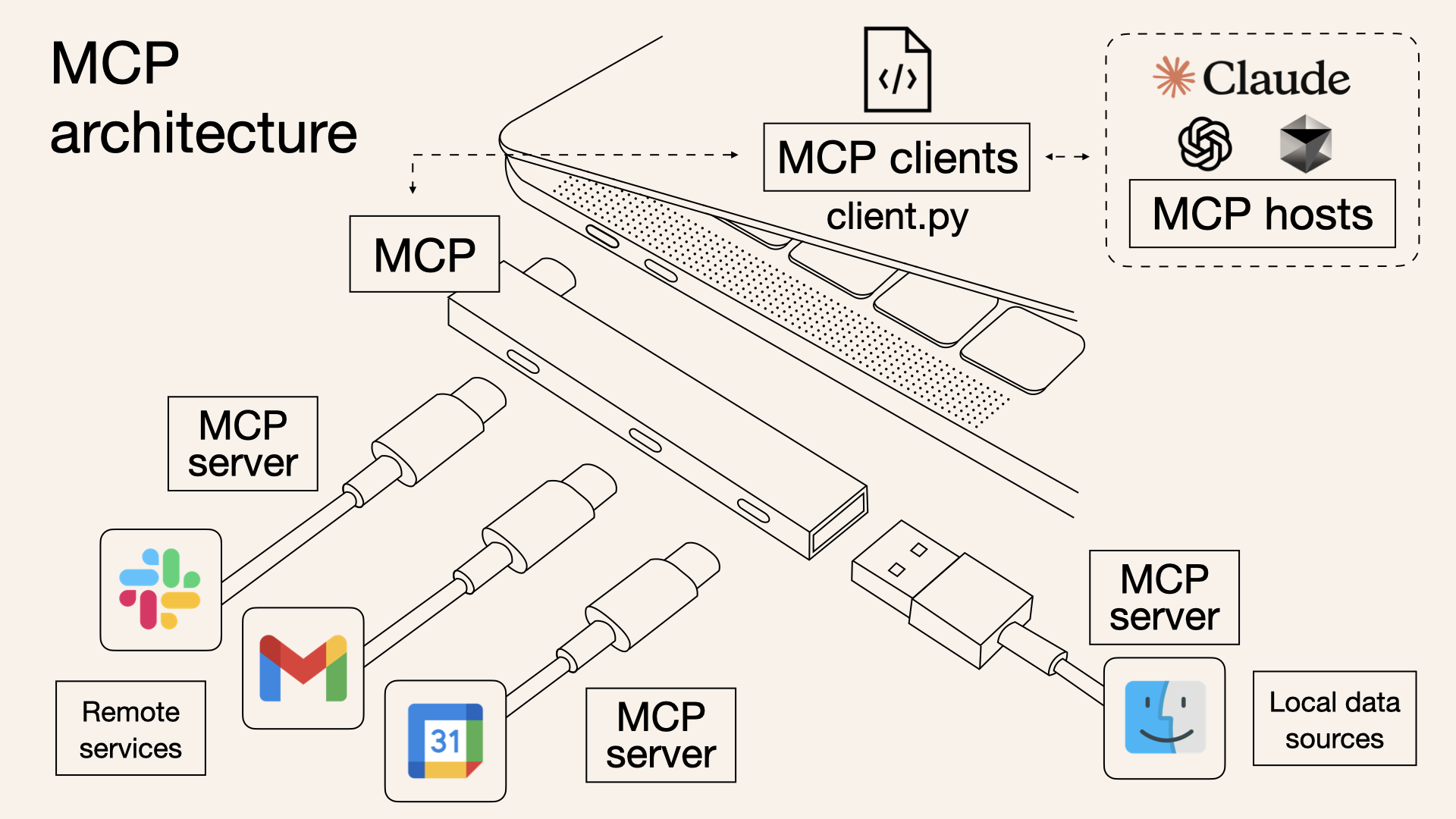
The Machines are the clients, external services and data sources are the peripherals (like Slack, Gmail, or local files), and MCP provides the ports in the middle that let them connect.
Image Credit: MCP as USB-C Port (LinkedIn Post)
🎯 Compared with LLM applications that directly connect to external resources, there is an additional middle layer (MCP Server) and the MCP Client that connects to this middle layer. If you understand these two, you will understand MCP.
What are the benefits of MCP?
This idea of a standard connector simplifies AI app development by offering these benefits:
- Simpler app development: With MCP, your application only needs to learn one standard method to communicate with the MCP server. This is similar to how API gateways make it easier to interact with multiple backend microservices.
- Plug-and-Unplug capabilities: You can easily connect or disconnect new MCP Servers at any time. If one server isn’t sufficient, you can add another. Anthropic’s Claude Desktop utilizes this concept to enhance its features, allowing you to mix, match, and upgrade capabilities.
- Easier updates & maintenance: If a tool like a weather API changes its interface, you only need to update the MCP Server that connects to it. All other applications using MCP will continue to work as usual.
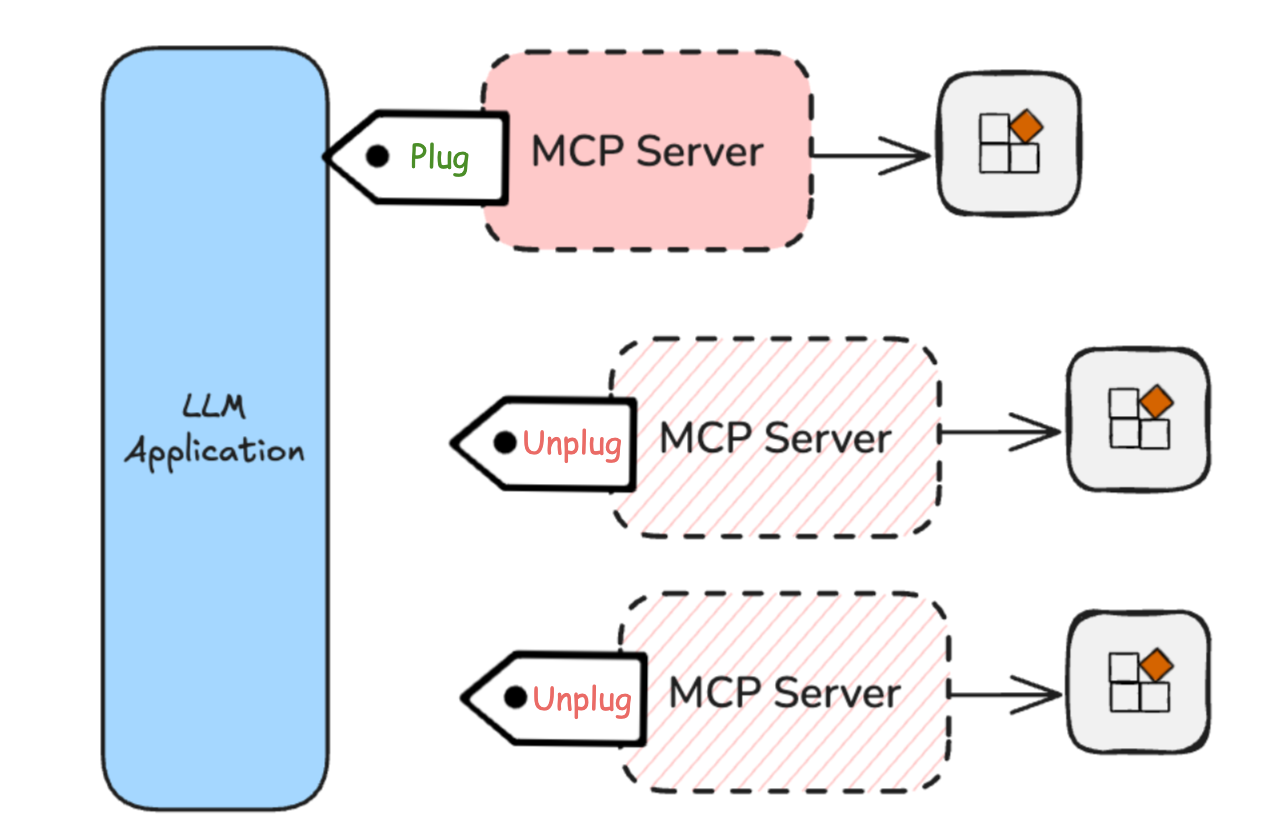
Image Credit: MCP benefits (BlogPost)
Understanding MCP’s Architecture
Now that we understand why we need MCP, let’s take a closer look at its architecture. Here’s an overview of MCP’s structure:
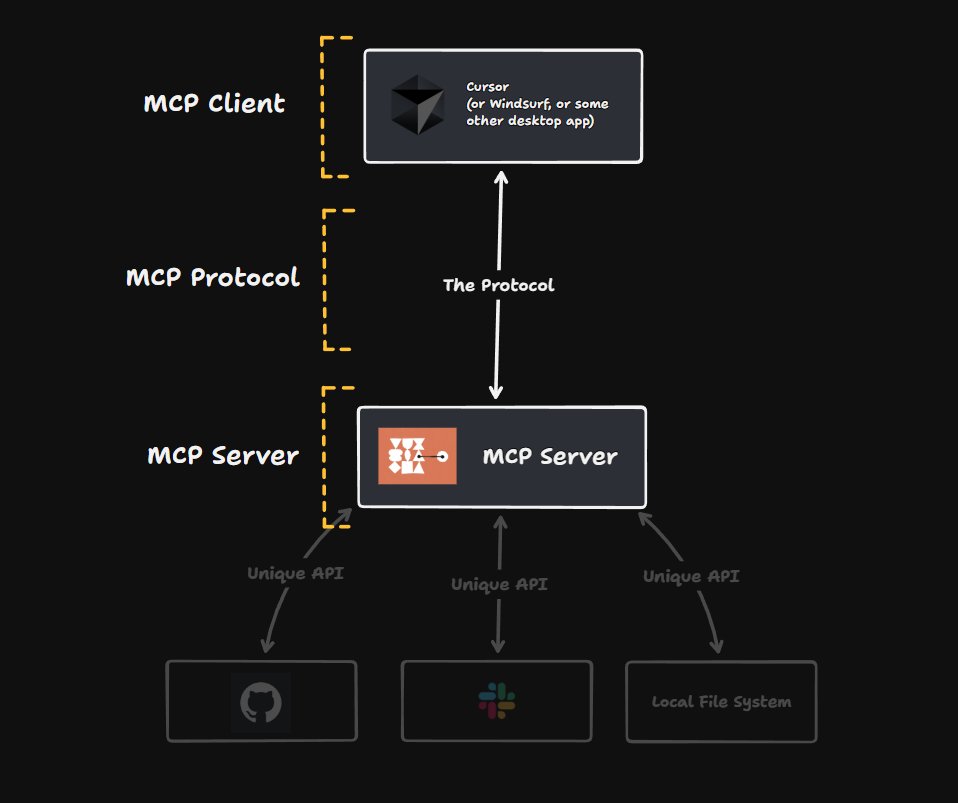
Image Credit: MCP architecture (Tweet threads by Matt Pocock)
MCP’s Building Blocks
The MCP architecture consists of three main pieces:
-
The Client:
- This is your app (like Cursor IDE or a chatbot).
- It connects directly to an MCP Server.
- Manages the conversation flow and knows which tools/data the server makes available.
-
The Protocol:
- The standard rules for how everything talks to each other.
- It defines how clients and servers must format messages to understand each other reliably.
- Handles things like security checks (authentication) and verifying available capabilities.
-
The Server:
- This is the backend engine connecting the LLM to outside world.
- Provides three key things:
Tools: Tools provided to LLM applications, especially Agents.Resources: Provides some additional structured data to the LLM application.Prompts: Some prompt templates provided to LLM applications. For example, if your application is a Chatbot, you can fetch these templates from the MCP Server and let users choose to use them.
MCP and RAG: Do we still need both 🤔 ?
This question comes up often: If MCP handles context and memory, and helps LLMs access external resources, is Retrieval-Augmented Generation (RAG) dead 💀? Short answer: Definitely not! They actually work great together.
Quick reminder: How RAG works
As It explained in the previous blog posts about RAG, traditional RAG follows these key steps:
- Indexing: Processing external data (chunking, embedding), then storing it in a searchable format (vectors) in a vector database.
- Retrieval: When a user asks a question, searching the index to find the most relevant chunks of information.
- Augmentation & Generation: Combining the retrieved information with the user’s original query and sending this package to the LLM to generate an answer.
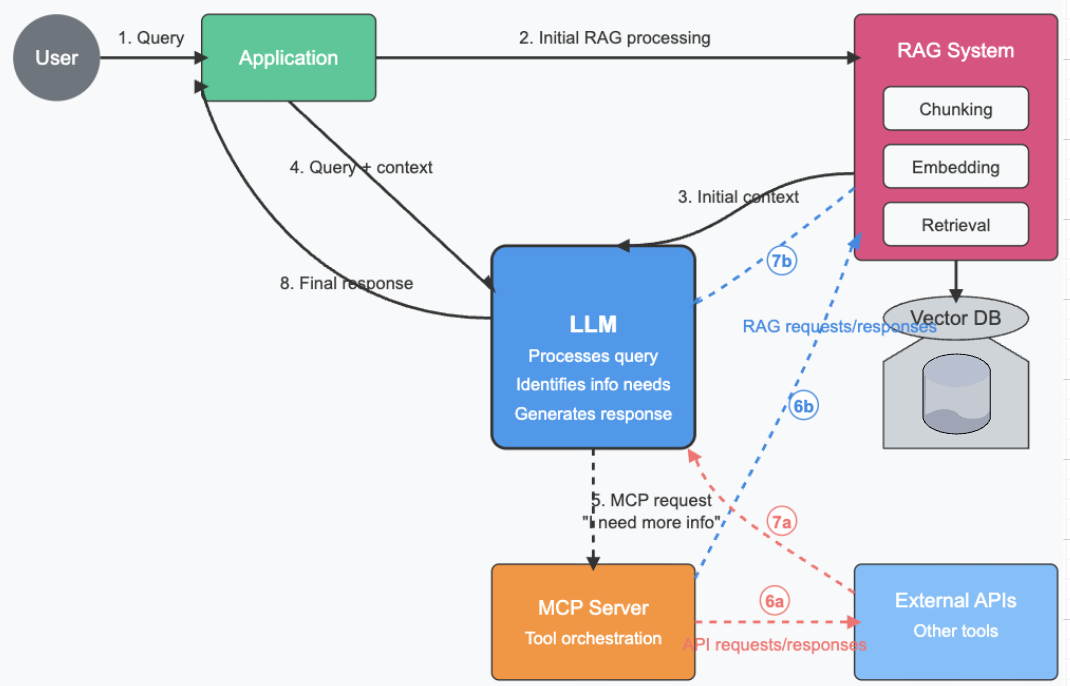
How MCP changes the approach
- User asks: The user writes a question directly to the LLM.
- LLM starts working: The LLM begins formulating an answer using its knowledge.
- LLM needs more info: During its thinking, the LLM might realize it needs more information. -> (e.g., “Hmm, I need to look up the latest news on this topic X.“)
- LLM requests help via MCP: Using the MCP standard, the LLM asks an external system to use a specific tool - which could be a RAG system.
- MCP server gets the data: The system processes the request, runs the appropriate tool, and sends back the information.
- Data goes back to LLM
- LLM completes the answer: With the additional context, the LLM finishes generating a more accurate response.
How They Work Together in Practice
The Key Difference: Timing and Control
In real-world implementations, you’ll often see both approaches used together:
- Initial context via RAG: Your application might use traditional RAG to provide relevant starting context.
- Follow-up retrieval via MCP: When the LLM identifies it needs additional information
duringgeneration, it can request more specific data through MCP.
Conclusion
We’ve walked through the Model Context Protocol (MCP): why it’s needed, how its architecture allows clients, servers, and protocols to work together, and how it works with techniques like RAG. MCP offers a promising path to supercharge LLM capabilities.
That wraps up our exploration of MCP concepts for this blog post. Stay tuned for the next blog where we’ll dive into the practical side – building an MCP server in Spring ecosystem using the Spring AI framework and connecting it with clients like Claude Desktop.