In the previous blog, we explored the core concepts of generative AI and Large Language Models (LLMs). Now, let’s dive deeper into the Retrieval-Augmented Generation (RAG) world and uncover the magic under the hood.
RAG: What is Retrieval-Augmented Generation?

Retrieval Augmented Generation, or RAG or RAG for short, is a powerful technique that takes Large Language Models (LLMs) to the next level. Instead of relying solely on what they already know, RAG connects LLMs to a universe of information beyond their initial training, allowing them to access and process the latest and most relevant data.
Here’s how it makes LLMs even better:
- Stay up-to-date: LLMs can retrieve the most current information, ensuring timely and relevant responses.
- Enhance accuracy: External knowledge provides valuable context, allowing LLMs to generate more accurate and comprehensive answers.
- Specialize in domains: Connecting LLMs to domain-specific knowledge bases allows them to become experts in particular fields.
In simple terms, RAG transforms LLMs from static knowledge repositories into dynamic, learning models that can continuously adapt and become powerful in understanding and interacting with the world.
Under the Hood of RAG: A Step-by-Step Breakdown
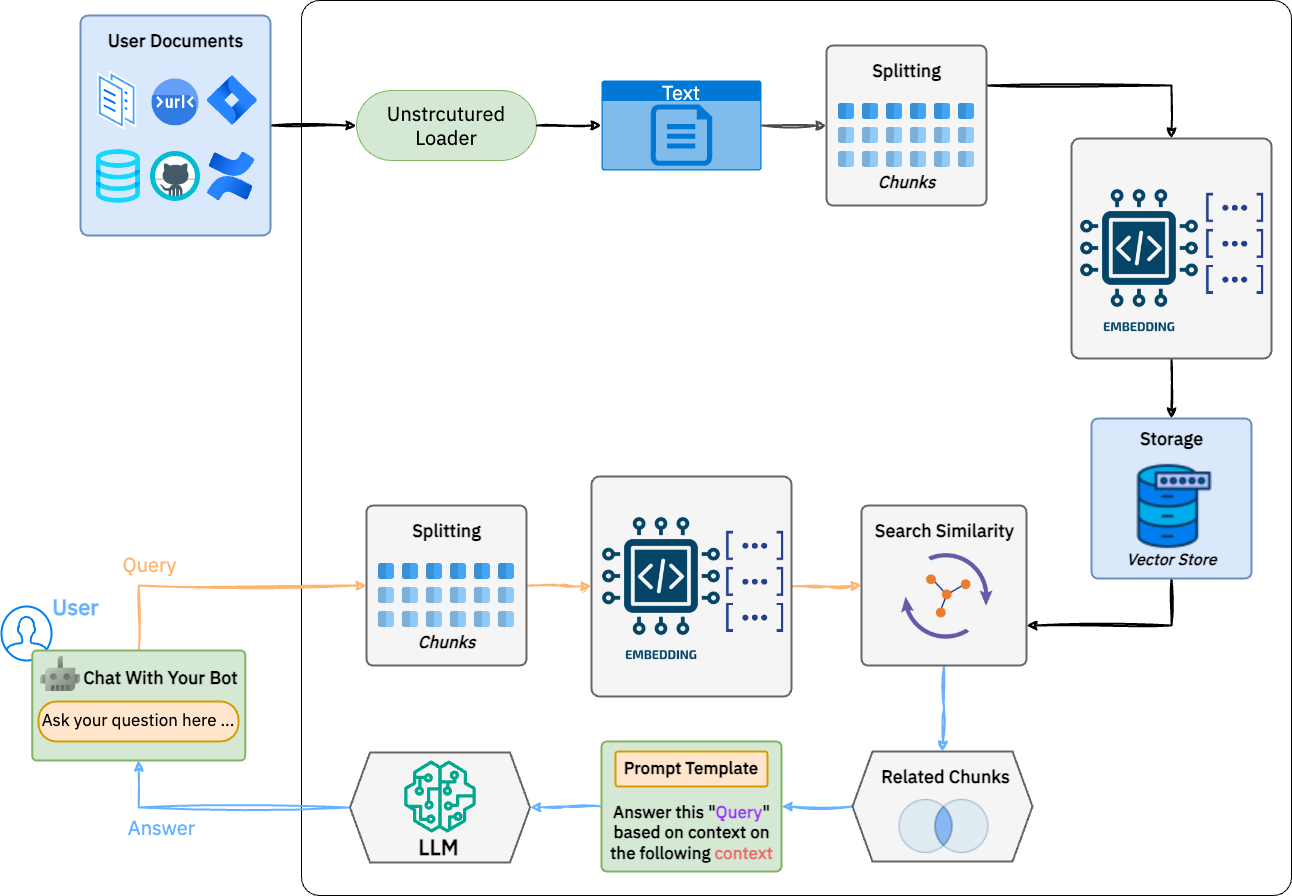
We’ve established that RAG empowers LLMs with external knowledge, but how does this magic happen? Let’s demystify and break down the process into digestible steps:
-
User Data Ingestion:
- The journey begins with gathering the knowledge to fuel our RAG system. This data can come from various sources, such as databases, PDF, TXT, Excel, video, audio, etc.
- We must carefully select documents relevant to the user’s input, allowing the LLM to respond based only on the provided context.
-
Splitting Data into Chunks:
- We come to a crucial technique known as
chunking. This is where the large volumes of data that we’ve ingested are broken down into smaller, more digestible pieces, orchunks. - Due to context window (i.e., the number of words the model can process at once), chunking is a necessary evil 😈!
2.1. Why & how are small chunks important?
- LLMs have a limited context window, meaning they can only process a certain number of words at a time, which means it’s unrealistic to process all our data to LLM at once.
- Splitting data into smaller parts makes it easier to work with and helps to find information more quickly. (i.e., a big book with lots and lots of pages). This lets the model focus on the most relevant details for a query.
2.2. Chunking strategies:
-
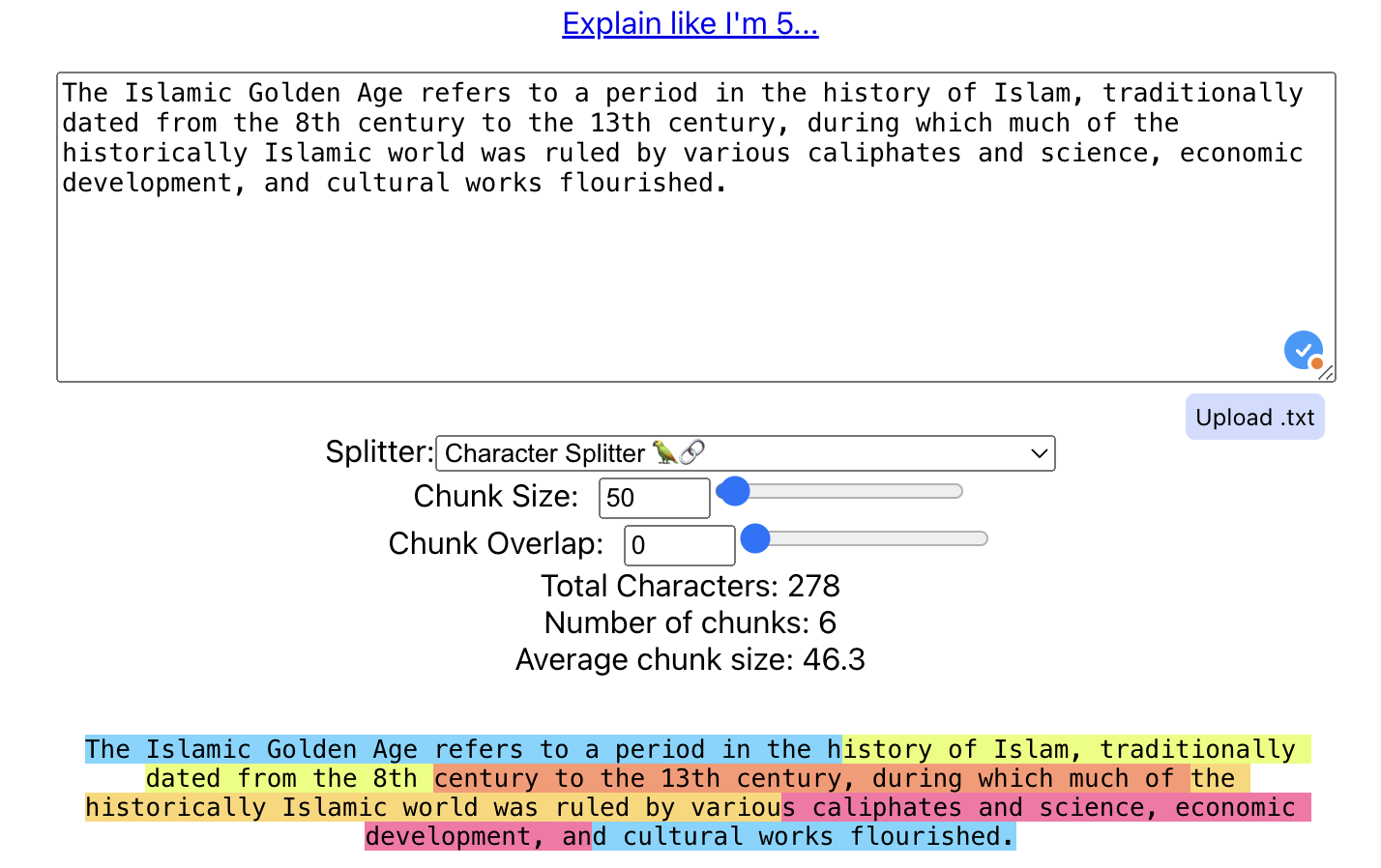
Let’s take a paragraph as an example where we will apply different chunking strategies to understand how they work:
“The Islamic Golden Age refers to a period in the history of Islam, traditionally dated from the 8th century to the 13th century, during which much of the historically Islamic world was ruled by various caliphates and science, economic development, and cultural works flourished.”
🔵
Chunking Size-
It’s a very basic strategy where we split the text into N-caracter sized chunks regardless of the content or its form.
-
Concepts to know:
- Chunk Size: The number of characters in each chunk. 50, 100, 1000, etc.
- Overlapping: The amount you would like your sequential chunks to overlap. This is to try to avoid cutting a single piece of context into multiple pieces. This will create duplicate data across chunks.
-
Small chunk size (50 caracteres, Overlapping 10):
Output: Chunk 1: The Islamic Golden Age refers to a period in the Chunk 2: Age refers to a period in the history of Islam Chunk 3: period in the history of Islam, traditionally Chunk 4: history of Islam, traditionally dated from the Chunk 5: traditionally dated from the 8th century to th Chunk 6: from the 8th century to the 13th century, dur Chunk 7: century to the 13th century, during which much Chunk 8: 13th century, during which much of the historic … Chunk 18: development, and cultural works flourished.
⚠️ Note : chunk is 50 characters long, and each new chunk starts 10 characters after the start of the previous chunk.
- Accurate retrieval on granular queries.
- Low contextual information for generation.
-
Large chunk size (200 caracteres, Overlapping 50):
Output: Chunk 1: The Islamic Golden Age refers to a period in the history of Islam, traditionally dated from the 8th century to the 13th century, during which much of the historically Islamic world was ruled by various caliphates and science, economic development, and cultural works flourished. Chunk 2: the historically Islamic world was ruled by various caliphates and science, economic development, and cultural works flourished.
- Chunks cover more information, less granular.
- Careful - too much information can lead to decreased accuracy and performance.
🔵
Recursive Chunking (Seperators: , . ;)-
Recursive chunking can be used to split the text into smaller chunks based on separators like commas, periods, or semicolons.
-
Based on the library you use, you can use default separators or define your own. Langchain for example …
Output (Recursive Chunking based on commas): Chunk 1: The Islamic Golden Age refers to a period in the history of Islam Chunk 2: traditionally dated from the 8th century to the 13th century Chunk 3: during which much of the historically Islamic world was ruled by various caliphates and science Chunk 4: economic development Chunk 5: cultural works flourished
🔵
Document Specific Chunking-
Chunking based on document-specific like markdown, JS, Python, etc.
-
For example, in markdown, we can split the text based on the following separators:
-
\n#{1,6}- Split by new lines followed by a header (H1 through H6) -
````\n` - Code blocks
-
\n\nDouble new lines -
\n- New line -
" "- Spaces -
""- Character
Input:
# Task planner for the week ## Monday - Meeting with the team - Review project timeline ## Tuesday - Client presentation - Code reviewOutput: Chunk 1: # Task planner for the week Chunk 2: ## Monday Chunk 3: - Meeting with the team Chunk 4: - Review project timeline Chunk 5: ## Tuesday Chunk 6: - Client presentation Chunk 7: - Code review
-
🔵
Semantic Chunking-
In this approach, chunks are created using embeddings, which means the text is converted into vectors and then split into semantically coherent chunks, meaning they make sense on their own and represent a complete thought or idea.
Output: Chunk 1: The Islamic Golden Age refers to a period in the history of Islam Chunk 2: traditionally dated from the 8th century to the 13th century Chunk 3: during which much of the historically Islamic world was ruled by various caliphates and science Chunk 4: economic development Chunk 5: cultural works flourished
💡 Takeaway: Your chunking strategy depends on what your data looks like and what you want to achieve.
- We come to a crucial technique known as
-
Data Embedding:
- Once we have our chunks, we need to convert them into a format that the LLM can understand. This is where
data embeddingcomes into play. - During this step, we transform raw chunk data into vector representations. This allows us to build a smart search engine that understands the meaning of words and sentences. Here an example of how data embedding works for a simple sentence:
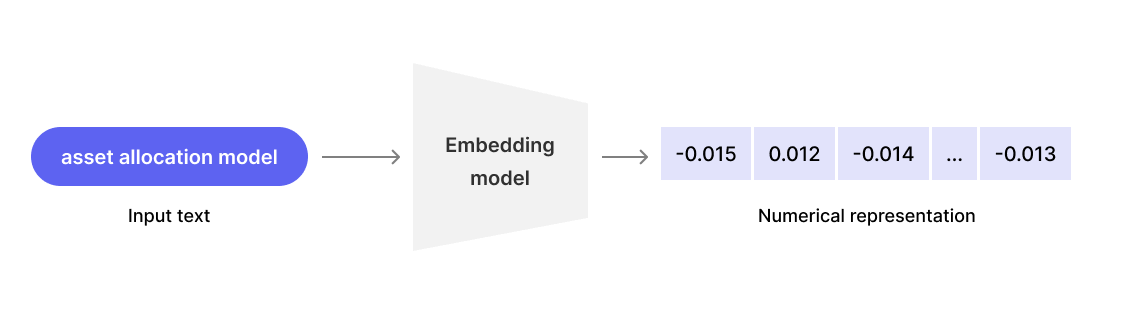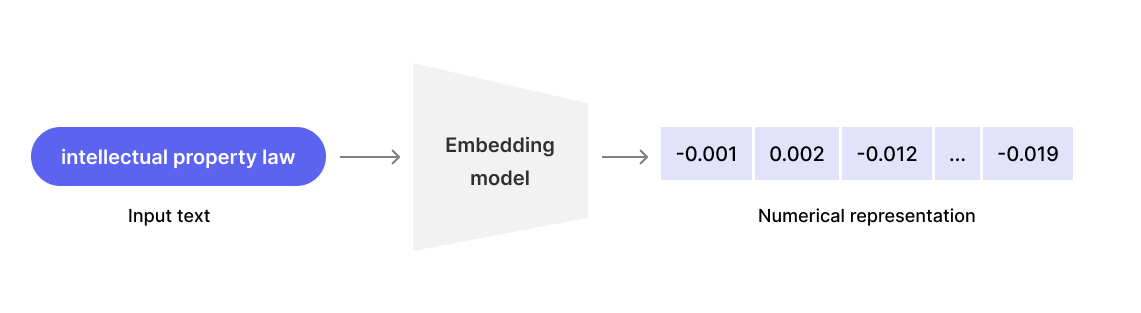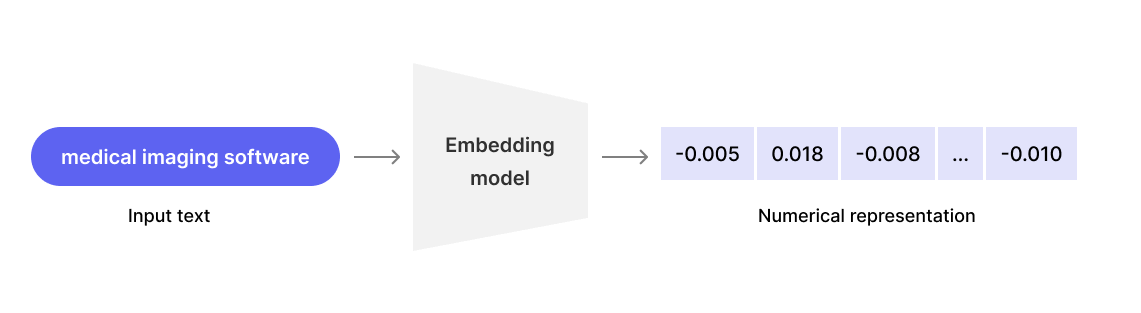
- Once we have our chunks, we need to convert them into a format that the LLM can understand. This is where
-
Storing Embeddings in a Vector Database:
- Once we have our data encoded into vectors through the embedding process. We store the vectors in databases engineered specifically for high-efficiency retrieval in a manner that optimizes both safety and speed of access.
- Databases like PgVector, Pinecone, and Chroma are popular choices for storing and retrieving embeddings.
-
Querying the Vector Database:
- User inputs (queries) are also chunked and embedded into a vector, like the knowledge base.
- The vector database calculates the similarity between the query vector and the stored document vectors.
How does the similarity calculation work ?
This stage is all about finding the closest match. By comparing the vector representation of the user’s query with the vectors of documents stored in our database, we initiate a search for the most similar entries. We use sophisticated algorithms known as Approximate Nearest Neighbor (ANN) searches to accomplish this. Here is a simple example demistifies of how similarity calculation works to find the closest match of a classic vehicle :
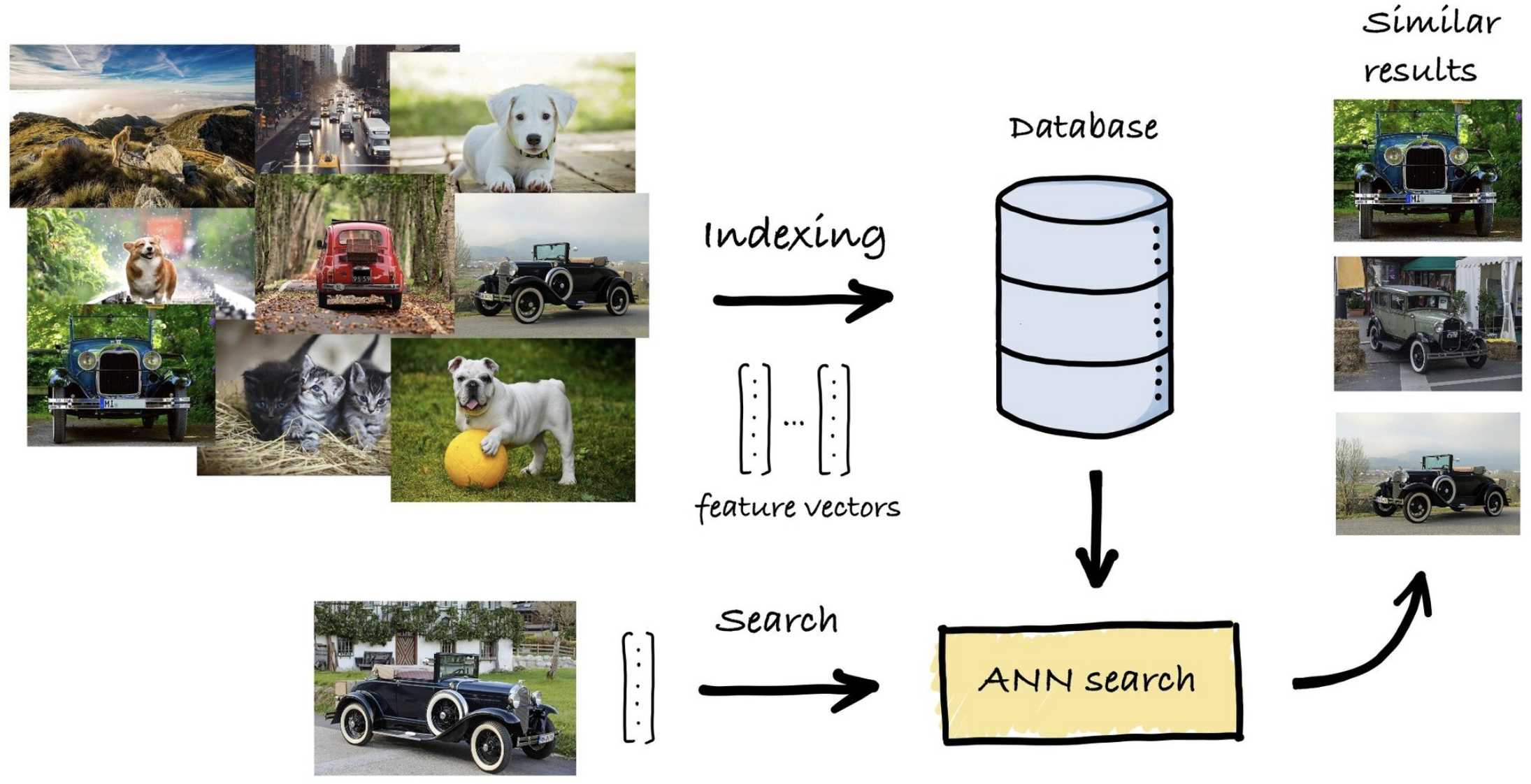
-
Generating the Final Response:
- We have now arrived at the final step in our exploration, after locating the relevant information through our vector similarity search, we provide this context to the LLM, allowing it to generate a response that is not only accurate but also contextually rich.
- Tataaa! We can now present the user response with the most relevant information 🎉.
Sometimes, a visual representation can help to understand complex processes better. Below is an animated illustration of the entire RAG process, with the main building blocks from user query to final response:
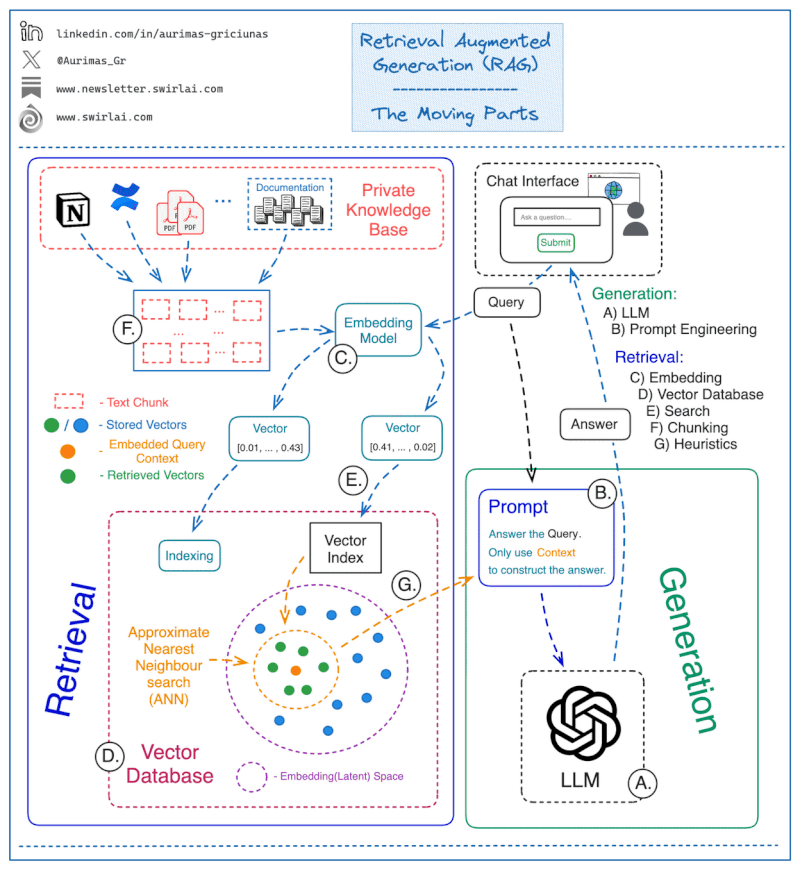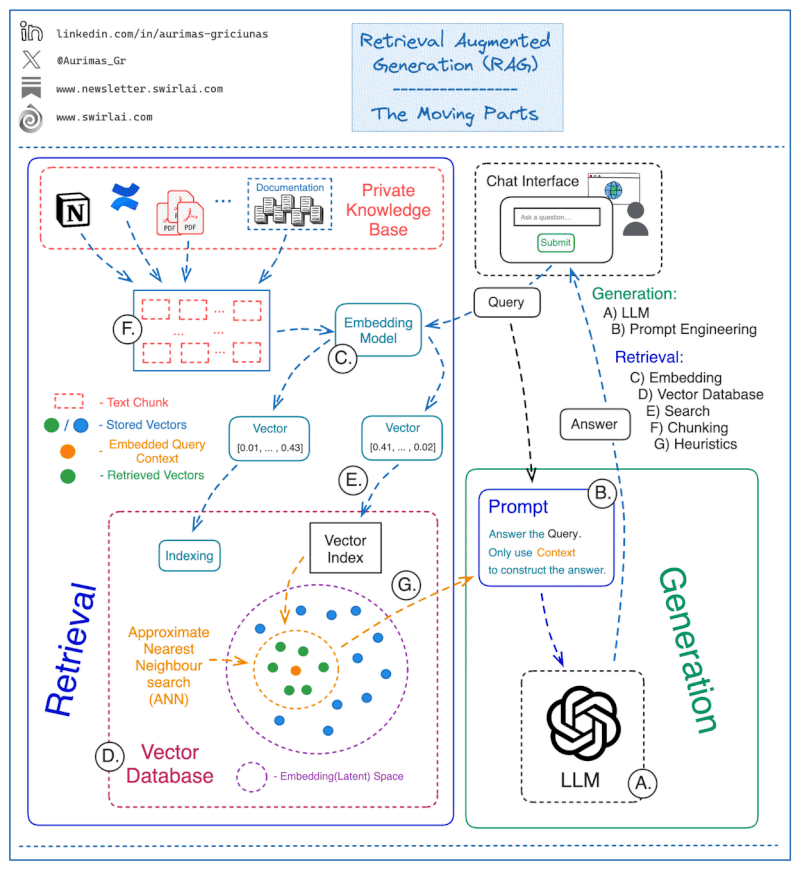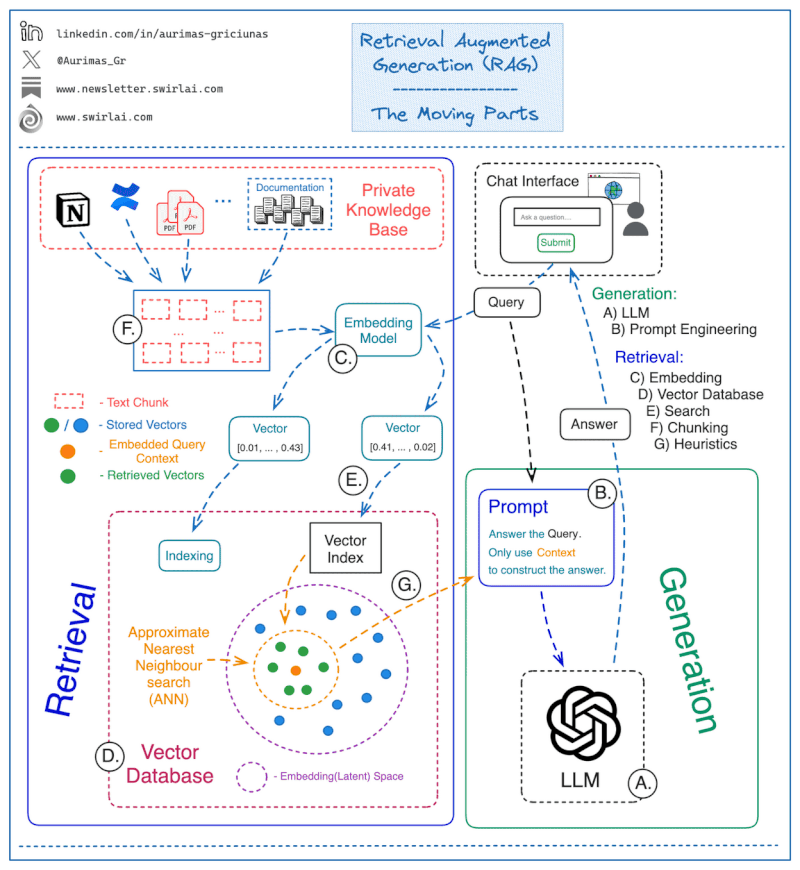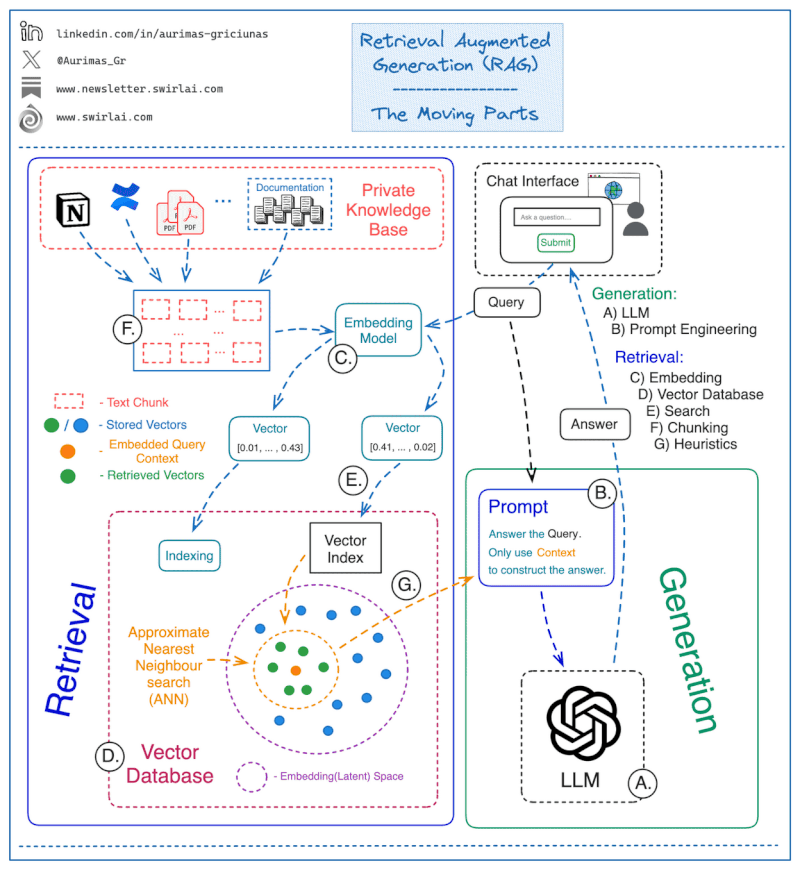 👤
👤 To sum up, RAG is a game-changer in the world of Large Language Models, offering a wealth of capabilities by connecting LLMs to external knowledge sources. The process, from data ingestion to response generation, is crucial in transforming static LLMs into dynamic, knowledge-rich models.
Looking ahead, we’ll delve into the leading frameworks in the Java ecosystem in our next blog post. We’ll compare how each framework implements these steps by providing examples and insights into their unique features.
Stay tuned, folks! 🚀