
Disclaimer 📢: I’m approaching LLMs and RAG from the lens of a passionate backend developer perspective, not as a data scientist or machine learning expert. My aim is to share my journey of exploration and understanding of Large Language Models (LLMs) and the Retrieval-Augmented Generation (RAG), their applications, and integrations within the Java ecosystem. I’m here to explore these big concepts with a focus on the practical side of things, rather than delving into the theoretical nitty-gritty.
Generative AI, LLMs, and RAG within AI Landscape
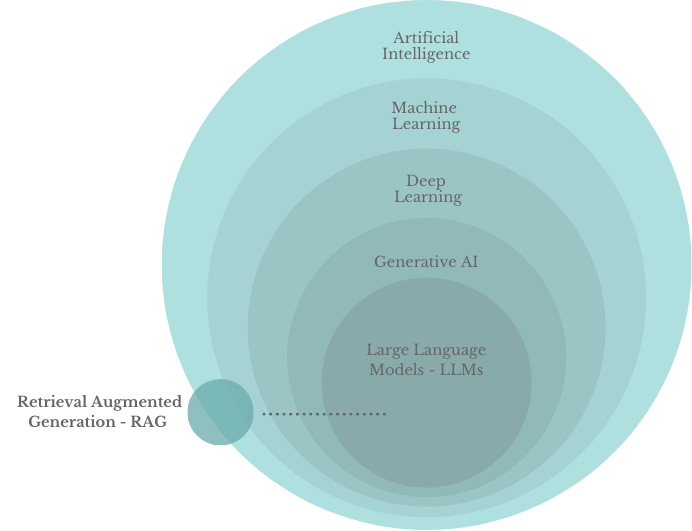
Think of Artificial Intelligence (AI) as a big toolbox filled with different techniques to make machines smarter. One powerful tool in this box is Deep Learning, which uses special algorithms called neural networks to learn from tons of data based on different patterns, like ANNs, CNNs, RNNs, and GANs.
Within Deep Learning, we also find generative AI, which focuses on creating/generating new content, such as text, images, videos, and even code. They’re like super-smart chatbots that can write code, translate languages, answer your questions comprehensively and creatively, … etc.
But even LLMs have their limits. That’s where RAG, or Retrieval Augmented Generation, comes in. RAG gives LLMs access to external knowledge sources for better answers and to generate more creative content with context.
Understanding Generative AI and its Star Player: GPT
The ability of machines to generate different kinds of content has become a hot topic in the tech world. But beyond the hype, what exactly does it mean, and how does it work? Let’s explore this fascinating field and spotlight on its most famous concept: GPT.
GPT stands for Generative Pre-trained Transformer, a type of Large Language Model (LLM) developed by OpenAI. Let’s break down what each part of the acronym means:
- G - Generative: Means “next word prediction” or “text generation”.
- P - Pre-trained: Models are trained on massive datasets from the internet and other sources.
- T - Transformer: Refers to the model architecture, which is a neural network architecture introduced in 2017 by Google in their paper “Attention is All You Need”
These powerful models have wowed us with their abilities and capabilities that have grown over the last few months. They can write essays, code faster often outperforming human developers, and even create videos, as demonstrated by OpenAI’s “Sora” model that generates videos, which is quite impressive and will be a game changer in the content creation industry in the near future.
Large Language Models (LLMs) - The Brains Behind Generative AI
Let’s take a closer look at the fascinating realm of Large Language Models, or LLMs. These complex neural networks possess remarkable abilities. But what exactly makes them tick ?
LLMs are built and trained on colossal datasets containing hundreds of billions of words, enabling them to develop a sophisticated understanding of language. For instance, OpenAI’s GPT-3 boasts 175 billion parameters, while models like Claude reach an astounding 500 billion. These parameters represent the model’s complexity and ability to process information. Think of them as the building blocks that allow LLMs to learn and generate an incredible range of content.
But LLMs aren’t just parrots repeating what they’ve read and trained on, they’re also adaptable. They can be fine-tuned and given additional information to become even more accurate and relevant to specific tasks.
Bigger is Better

The above image shows fundamental truth about the evolution of Large Language Models - size of the model equal to the skill.
By increasing the parameters, and we say increasing parameters means enhancing the token numbers, our models are not just growing; they’re evolving to understand and interact in incredible ways. This is the power of scale - a model with more parameters can juggle complex tasks.
LLMs Know Two Things: Few-Shot Learning and Fine-Tuning
The adaptability and intelligence of LLMs open doors to exciting possibilities. Let’s discover the two main approaches to unlock their potential ; few-short learning and fine-tuning.
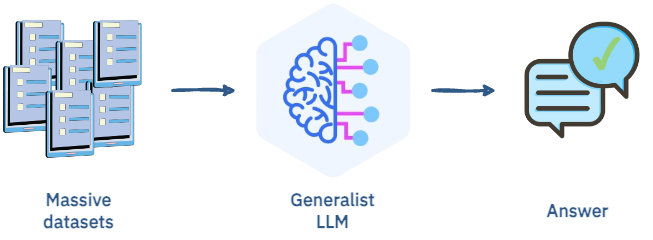
First, there’s Few-Shot Learning, which utilizes carefully crafted prompts to guide generalist LLMs in understanding and solving problems with minimal examples. This means that with just a few demonstrations, the model can grasp the essence of a task and generate accurate results. This approach significantly reduces the need for extensive training data.
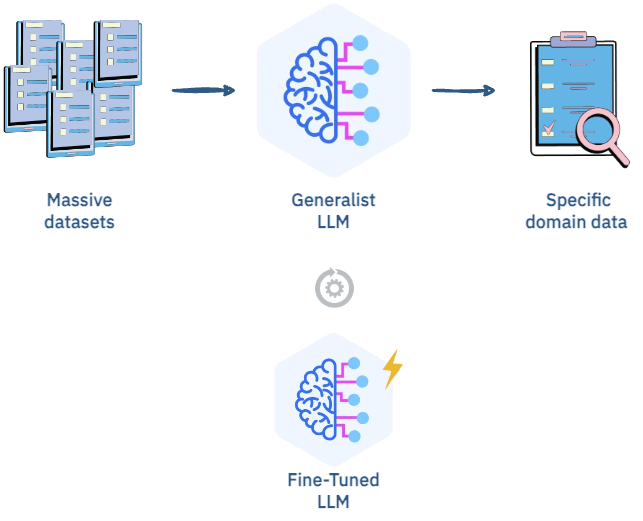
Next, there’s Fine-Tuning which allows you to customize the model to your needs. By providing relevant data as context, the model adapts to your specific use case and generates more precise and relevant outputs.
Tackling Hallucinations and Misinformation with LLMs

While we’ve discussed the remarkable abilities of LLMs, it’s crucial to address that they are not without their weakness. One such limitation is what we call hallucinations. This is a term we use when an LLM confidently presents information that is either incorrect or does not exist in reality.

Take the example above: the model is asked to solve 34+99, and it provides the answer ‘99’. It’s a confident response, but it’s wrong. He rectifies the answer while developing the answer.
We must remember that these models, as advanced as they are, still require careful oversight and verification. They can be incredibly powerful tools, but their outputs must always be carefully reviewed, because sometimes they can generate inaccurate or misleading content.
Optimizing LLMs
In the face of limitations like hallucinations and misinformation, the question arises: How do we optimize Large Language Models for better performance?
The following matrix shows us some techniques to enhance LLMs, both in terms of their behavior and the context they can handle.
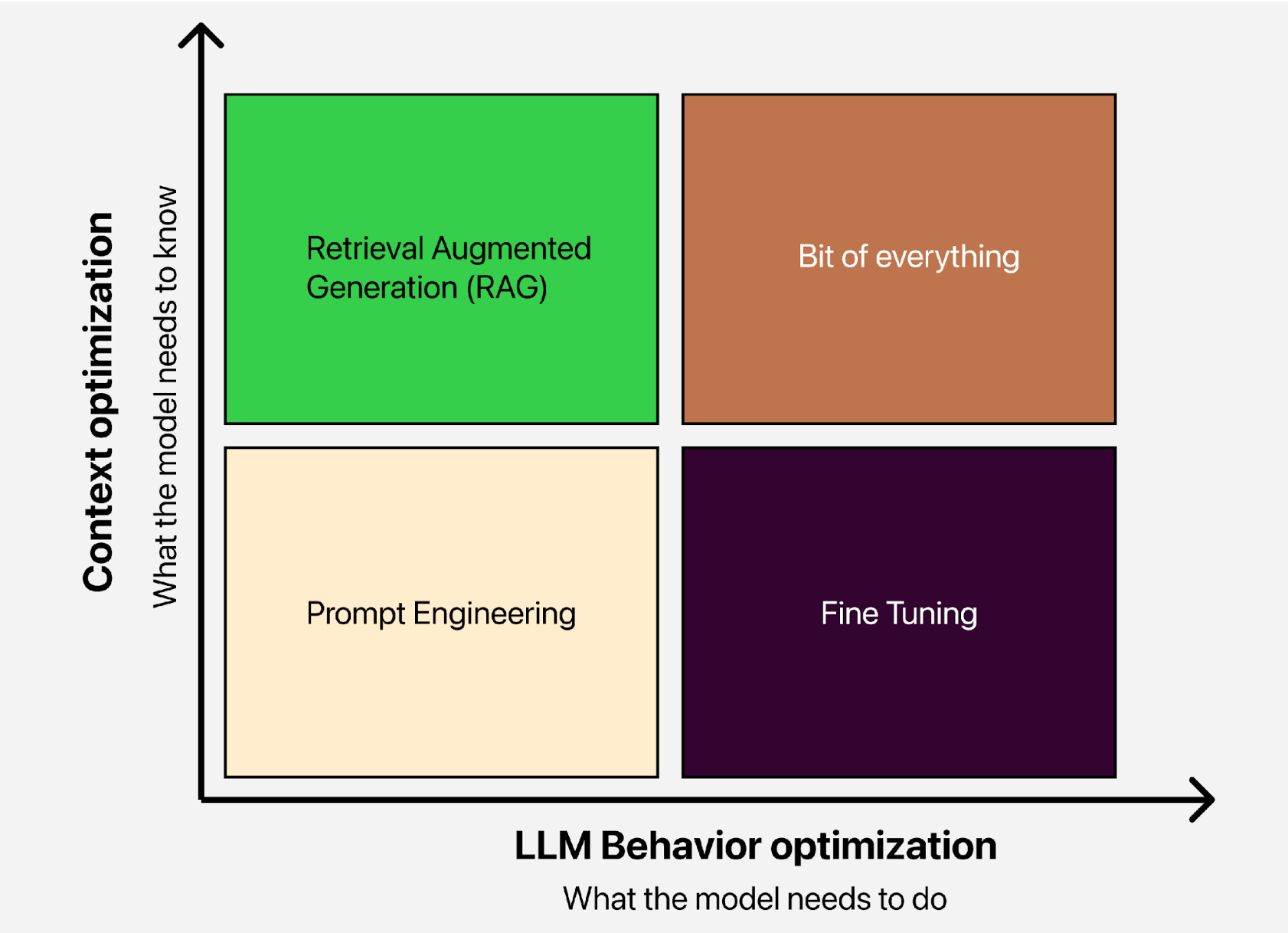 We can employ techniques like prompt engineering by crafting better prompts to guide the model in generating more accurate and relevant content. Fine-tuning that we’ve already discussed, also a bit of everything, which means combining different techniques to optimize the model’s performance. And lastly, there’s RAG, or Retrieval-Augmented Generation, which we’ll delve into in the next blog where we’ll explore how it works and its applications in real-world scenarios.
We can employ techniques like prompt engineering by crafting better prompts to guide the model in generating more accurate and relevant content. Fine-tuning that we’ve already discussed, also a bit of everything, which means combining different techniques to optimize the model’s performance. And lastly, there’s RAG, or Retrieval-Augmented Generation, which we’ll delve into in the next blog where we’ll explore how it works and its applications in real-world scenarios.
That’s all folks! I hope you enjoyed this comprehensive overview of Generative AI and Large Language Models and found it enlightening. Keep an eye out for our next blog, where we’ll delve into Retrieval-Augmented Generation (RAG) and examine its uses and integrations within the Java and Spring Boot ecosystem. Until then, happy coding! 🚀